第六章:深度学习
在上一章,我们学习了深度神经网络通常比浅层神经网络更加难以训练。我们有理由相信,若是可以训练深度网络,则能够获得比浅层网络更加强大的能力,但是现实很残酷。从上一章我们可以看到很多不利的消息,但是这些困难不能阻止我们使用深度神经网络。本章,我们将给出可以用来训练深度神经网络的技术,并在实战中应用它们。同样我们也会从更加广阔的视角来看神经网络,简要地回顾近期有关深度神经网络在图像识别、语音识别和其他应用中的研究进展。然后,还会给出一些关于未来神经网络又或人工智能的简短的推测性的看法。
这一章比较长。为了更好地让你们学习,我们先粗看一下整体安排。本章的小结之间关联并不太紧密,所以如果读者熟悉基本的神经网络的知识,那么可以任意跳到自己最感兴趣的部分。
本章主要的部分是对最为流行神经网络之一的深度卷积网络的介绍。我们将细致地分析一个使用卷积网络来解决 MNIST 数据集的手写数字识别的例子(包含了代码和讲解):
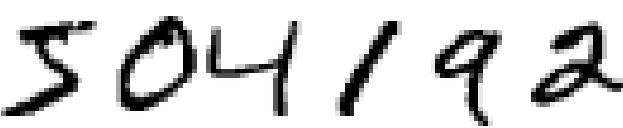
我们将从浅层的神经网络开始来解决上面的问题。通过多次的迭代,我们会构建越来越强大的网络。在这个过程中,也将要探究若干强大技术:卷积、pooling、使用GPU来更好地训练、训练数据的算法性扩展(避免过度拟合)、dropout 技术的使用(同样为了防止过度拟合现象)、网络的 ensemble 使用和其他技术。最终的结果能够接近人类的表现。在 10,000 幅 MNIST 测试图像上 —— 模型从未在训练中接触的图像 —— 该系统最终能够将其中 9,967 幅正确分类。这儿我们看看错分的 33 幅图像。注意正确分类是右上的标记;系统产生的分类在右下:

可以发现,这里面的图像使对于人类来说都是非常困难区分的。例如,在第一行的第三幅图。我看的话,看起来更像是 “9” 而非 “8”,而 “8” 却是给出的真实的结果。我们的网络同样能够确定这个是 “9”。这种类型的“错误”最起码是容易理解的,可能甚至值得我们赞许。最后用对最近使用深度(卷积)神经网络在图像识别上的研究进展作为关于图像识别的讨论的总结。
本章剩下的部分,我们将会从一个更加宽泛和宏观的角度来讨论深度学习。概述一些神经网络的其他模型,例如 RNN 和 LSTM 网络,以及这些网络如何在语音识别、自然语言处理和其他领域中应用的。最后会试着推测一下,神经网络和深度学习未来发展的方向,会从 intention-driven user interfaces 谈谈深度学习在人工智能的角色。这章内容建立在本书前面章节的基础之上,使用了前面介绍的诸如 BP、规范化、softmax 函数,等等。然而,要想阅读这一章,倒是不需要太过细致地掌握前面章节中内容的所有的细节。当然读完第一章关于神经网络的基础是非常有帮助的。本章提到第二章到第五章的概念时,也会在文中给出链接供读者去查看这些必需的概念。
需要注意的一点是,本章所没有包含的那一部分。这一章并不是关于最新和最强大的神经网络库。我们也不是想训练数十层的神经网络来处理最前沿的问题。而是希望能够让读者理解深度神经网络背后核心的原理,并将这些原理用在一个 MNIST 问题的解决中,方便我们的理解。换句话说,本章目标不是将最前沿的神经网络展示给你看。包括前面的章节,我们都是聚焦在基础上,这样读者就能够做好充分的准备来掌握众多的不断涌现的深度学习领域最新工作。本章仍然在Beta版。期望读者指出笔误,bug,小错和主要的误解。如果你发现了可疑的地方,请直接联系 mn@michaelnielsen.org。