2.4 反向传播的四个基本方程
反向传播其实是对权重和偏置变化影响代价函数过程的理解。最终极的含义其实就是计算偏导数 和 。但是为了计算这些值,我们首先引入一个中间量,,这个我们称为在 层第 个神经元上的误差。
反向传播将给出计算误差 的流程,然后将其关联到计算 和 上
为了理解误差是如何定义的,假设在神经网络上有一个调皮鬼:

这个调皮鬼在 层的第 个神经元上。当输入进来时,调皮鬼对神经元的操作进行搅局。他会增加很小的变化 在神经元的带权输入上,使得神经元输出由 变成 。这个变化会向网络后面的层进行传播,最终导致整个代价产生 的改变。
现在,这个调皮鬼变好了,试着帮助你来优化代价,它试着找到可以让代价更小的 。假设 有一个很大的值(或正或负)。那么这个调皮鬼可以通过选择与 相反符号的 来降低代价。相反,如果 接近 ,那么调皮鬼并不能通过扰动带权输入 来改善太多代价。在调皮鬼看来,这时候神经元已经很接近最优了2。所以这里有一种启发式的认识, 是神经元的误差的度量。
按照上面的描述,我们定义 层的第 个神经元上的误差 为:
按照我们通常的惯例,我们使用 表示关联于 层的误差向量。反向传播会提供给我们一种计算每层的 的方法,然后将这些误差和最终我们需要的量 和 联系起来。
你可能会想知道为何这个调皮鬼在改变带权输入 。把它想象成改变输出激活值 肯定会更加自然,然后就使用 作为度量误差的方法了。实际上,如果你这样做的话,其实和下面要讨论的差不多。但是看起来,前面的方法会让反向传播在代数运算上变得比较复杂。所以我们坚持使用 作为误差的度量3。
解决方案: 反向传播基于四个基本方程。这些方程给我们一种计算误差 和代价函数梯度的方法。我列出这四个方程。但是需要注意:你不需要一下子能够同时理解这些公式。希望越大失望越大。实际上,反向传播方程内容很多,完全理解这些需要花费充分的时间和耐心,需要一步一步地深入理解。而好的消息是,这样的付出回报巨大。所以本节对这些内容的讨论仅仅是一个帮助你正确掌握这些方程的起步。
下面简要介绍我们的探讨这些公式的计划:首先给出这些公式的简短证明以解释他们的正确性;然后以伪代码的方式给出这些公式的算法形式,并展示这些伪代码如何转化成真实的可执行的 Python 代码;在本章的最后,我们会发展出一个关于反向传播方程含义的直觉画面,以及人们如何能够从零开始发现这个规律。按照此法,我们会不断地提及这四个基本方程,随着你对这些方程理解的加深,他们会看起来更加舒服,甚至是美妙和自然的。
输出层误差的方程,: 每个元素定义如下:
这是一个非常自然的表达式。右式第一个项 表示代价随着 输出激活值的变化而变化的速度。假如 不太依赖一个特定的输出神经元 ,那么 就会很小,这也是我们想要的效果。右式第二项 刻画了在 处激活函数 变化的速度。
注意到在 (BP1) 中的每个部分都是很好计算的。特别地,我们在计算网络行为时计算 ,这仅仅需要一点点额外工作就可以计算 。当然 依赖于代价函数的形式。然而,给定了代价函数,计算 就没有什么大问题了。例如,如果我们使用二次函数,那么 ,所以 ,这其实很容易计算。
方程 (BP1) 对 来说是个按分量构成的表达式。这是一个非常好的表达式,但不是我们期望的用矩阵表示的形式。但是,以矩阵形式重写方程其实很简单,
这里 被定义成一个向量,其元素是偏导数 。你可以将 看成是 关于输出激活值的改变速度。方程 (BP1) 和方程 (BP1a) 的等价也是显而易见的,所以现在开始,我们会用 (BP1) 表示这两个方程。举个例子,在二次代价函数时,我们有 ,所以 (BP1) 的整个矩阵形式就变成
如你所见,这个方程中的每个项都有一个很好的向量形式,所以也可以很方便地使用像 Numpy 这样的矩阵库进行计算了。
使用下一层的误差 来表示当前层的误差 :特别地,
其中 是 层权重矩阵 的转置。这个公式看上去有些复杂,但每一个元素有很好的解释。假设我们知道 层的误差 。当我们应用转置的权重矩阵 ,我们可以凭直觉地把它看作是在沿着网络反向移动误差,给了我们度量在 层输出的误差方法。然后,我们进行 Hadamard 乘积运算 。这会让误差通过 层的激活函数反向传递回来并给出在第 层的带权输入的误差 。 通过组合 (BP1) 和 (BP2),我们可以计算任何层的误差 。首先使用 (BP1) 计算 ,然后应用方程 (BP2) 来计算,然后再次用方程 (BP2) 来计算 ,如此一步一步地反向传播完整个网络。
代价函数关于网络中任意偏置的改变率: 就是
这其实是,误差 和偏导数值 完全一致。这是很好的性质,因为 (BP1) 和 (BP2) 已经告诉我们如何计算 。所以就可以将 (BP3) 简记为
其中 和偏置 都是针对同一个神经元。
代价函数关于任何一个权重的改变率: 特别地,
这告诉我们如何计算偏导数 ,其中 和 这些量我们都已经知道如何计算了。方程也可以写成下面用更少下标的表示:
其中 是输入给权重 的神经元的激活值, 是输出自权重 的神经元的误差。放大看看权重 ,还有两个由这个权重相连的神经元,我们给出一幅图如下:
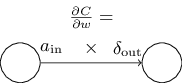
方程 (32) 的一个好的结果就是当激活值 很小,,梯度 也会趋向很小。这样,我们就说权重缓慢学习,表示在梯度下降的时候,这个权重不会改变太多。换言之,(BP4) 的一个结果就是来自低激活值神经元的权重学习会非常缓慢。
这四个公式 (BP1)--(BP4) 同样还有其它可以理解的方面。让我们从输出层开始,先看看 (BP1) 中的项 。回忆一下上一章中 S 型函数的图形,当 近似为 或者 的时候 函数变得非常平。这时 。所以如果输出神经元处于或者低激活值()或者高激活值()时,最终层的权重学习缓慢。这样的情形,我们常常称输出神经元已经饱和了,并且,权重学习也会终止(或者学习非常缓慢)。类似的结果对于输出神经元的偏置也是成立的。
针对前面的层,我们也有类似的观点。特别地,注意在 (BP2) 中的项 。这表示如果神经元已经接近饱和, 很可能变小。这就导致任何输入进一个饱和的神经元的权重学习缓慢4。
总结一下,我们已经学习到,如果输入神经元激活值很低,或者输出神经元已经饱和了(过高或者过低的激活值),权重会学习缓慢。
这些观测其实也不是非常出于意料的。不过,他们帮助我们完善了关于神经网络学习的背后的思维模型。而且,我们可以将这种推断方式进行推广。四个基本方程也其实对任何的激活函数都是成立的(证明中也可以看到,其实推断本身不依赖于任何具体的代价函数)所以,我们可以使用这些方程来设计有特定学习属性的激活函数。我们这里给个例子,假设我们准备选择一个(非S型)激活函数 使得 总是正数,并且不会趋近 。这会防止在原始的S型神经元饱和时学习速度下降的情况出现。在本书的后面,我们会见到这种类型的对激活函数的改变。时时回顾这四个方程(BP1)--(BP4) 可以帮助解释为何需要有这些尝试,以及尝试带来的影响。

问题
另一种反向传播方程的表示方式: 我已经给出了使用 Hadamard 乘积的反向传播的公式(尤其是 (BP1) 和 (BP2))。如果你对这种特殊的乘积不熟悉,可能会有一些困惑。下面还有一种表示方式,那就是基于传统的矩阵乘法,某些读者可能会觉得很有启发。(1)证明 (BP1) 可以写成
其中 是一个方阵,其对角线的元素是 ,其他的元素均是 。注意,这个矩阵通过一般的矩阵乘法作用在 上。(2)证明(BP2) 可以写成
(3)结合(1)和(2)证明
对那些习惯于这种形式的矩阵乘法的读者,(BP1) (BP2) 应该更加容易理解。而我们坚持使用 Hadamard 乘积的原因在于其更快的数值实现。
2. 这里需要注意的是,只有在 很小的时候才能够满足。我们需要假设调皮鬼只能进行微小的调整。 ↩
3. 在分类问题中,误差有时候会用作分类的错误率。如果神经网络正确分类了 96.0% 的数字,那么其误差是 4.0%。很明显,这和我们上面提及的误差的差别非常大了。在实际应用中,区分这两种含义是非常容易的。 ↩
4. 如果 拥有足够大的量能够补偿 的话,这里的推导就不能成立了。但是我们上面是常见的情形。 ↩